����ʱ�䣺2018-06-13 10:57 ��ҪͶ��
��������/ �۲�����ר������ �¾���
����2016��2017��ĩ�����������ڣ������Ǿ�ϲ�ط���Χ�������վ�����˺ü�����ˮƽΧ��AI��
�������ij�������ģһ��һֱ���µ����ձ���DEEPZEN����2017��1��3������ʱ���Ѿ����˳���200�̣�����20�̡�֮ǰDEEPZEN�ڸ��ֲ����KGSΧ������Ҳ����ô���£������Ѿ���Ϥ�����ķ��DEEPZEN���ijǵ�ս�������������ϣ������е�����ʧ������Ȼ��ʤ�ฺ�٣�����Ҫ��ʤ����P��־��ҵ�����֣���ְҵ������ö࣬��û������ھ������ֳ���������
������һ��һ���߾�������ע������ѶҰ��Χ��ġ����족����Ѷ��2016��11�����ߵ�AI�����ա���һ�������Ѿ�����˲�С��������ʤ�˿½�һ�̣�5��1ʤ��͢�����������ǶԹ���AI�������ģ���ѶҲ������2017��3�����ձ��ٰ��AIΧ����������������Ǹ������ƺ������˾��յ�·���ҵ��˶Ը����İ취���½�Ծ��յ�ս����3��1������ְҵ���ֶ�սʤ���������ճ���һЩ���Ե�bug����˴�11�µף�������û�¹��壬�����з�����ȥ�ˡ�
����һ���º�2016��12��27�գ������汾�����족�����߿�ʼ���塣�������Ӧ���н������Կ½�ս��5��2������͢��4��1��������˵�б��ʽ������½������ҵ��˶Ը����İ취�����γ������Ĵ�������������������⡣��Щ������ȫ����20���30��һ�ֵĿ��壬���������ھ��������ǵ�ʤ�����ܴ�̶��Ǹ�������Ϊʱ��ѹ�����ִ�����½���һ���Ѿ�ɱ��������Ĵ����������ƣ����治С�����ȥ�ˡ���Ѷ������AIˮƽ�Ѿ��ܸ��ˣ�ְҵ���ָо�����ʵ����2016��3��������ʯ��ս��AlphaGo�汾V18�൱��ְҵ�������Ѿ��ҵ��������©���������а취�˲���̫�¡�

������ͼ��2016��12��30�տ½��һ�ζ���ʤ���죬��ִ�ڴ�ʤ�����ֿ½�����ͳԵ����������ұߵ�һ��������������п½������������������������壬�������������Ա�ֶ������������ˡ�AI����߳��������壬��ʹһʱ���������ʤ�ฺ�٣�������Ҳ�����¡�
������ʱ�ij���վ�ϵ�Master��2016��12��29��Ҳ��ʼ�����ˣ�һ��ʼ�������˹�ע����ʼ10���ʤ�IJ���������ھ������֡�����12��30��Master��������һ�ڶ��Ŀ½�����͢����ʤ2��ȡ��20��ʤ�����������˹�ע�����������ֲ�����̫�Ծ�����Ϊ֮ǰ����������Ҳ�������ľ��ޱ��֣�����Master�µ���20��Ŀ��壬20��ʱ��̫�̸�����������30������ǻ�ö��ˡ�
����������ϲ���ձ�����ô���ˮƽ��AIͬʱ�ڶ�����վ�ϣ�AlphaGo������������һ�ѹ��У���Ⱥ�������ꡱ̫����˼�ˡ�������ְҵ���ֺ���������Ȼ��Ԥ���ǣ�����ÿ��ʱ��������30�룬������������ĥҲ�ҵ�Master��©������ʤ����������Ԥ�ں������ࡣ
��������ʵ֤����Master��ˮƽ������Ҫ�ߵöࡣ���ijǴ��30��ʤ��MasterתսҰ������1��1��������Ϣ��һ�죬����ÿ��10�ֵĽ��ࡣ��2017��1��3�գ�Master�����50��ʤ�������а���16λ����ھ�������ˮƽ��ߵĿ½ࡢ��͢������ɽԣ̫�������С�����������Ŷ���������һ��͵��±��Ű�̧�ߡ�����һʤ��������û�г��ֹ�ʤ����������һ���ֲ��ʹ�Ϊ���Master��������10��Ŀ����20Ŀ���ϣ��չ�ʱ�١��á�������һЩĿ���ͳ�4Ŀ�롢2Ŀ����߰�Ŀʤ��
��������ˮƽ��ߵ�����Ⱥ�壬��Master��ǰ����©���ٳ�������һЩְҵ�����Լ���������Щ���Խ��ܡ�
����Master����������
����Master��������Ȼ����AlphaGo�������汾���Ҷ϶�û���������ܡ�Master���ij�ע��Ϊ����ְҵ���֣�������ΪAlphaGoʤ������ʯ�����˺�����Ժ�䷢�ľŶ�֤�顣1����ǰ��KGS��Ԫ����ŰɱDEEPZEN��GodMoves�ܿ���Ҳ��AlphaGo��Ӧ���Ƿ�CPU��GPU���ٵĵ����浽����վ���ԡ��ȸ���11������AlphaGoȡ���˾����������2017����������塣�ȸ�CEO���������й���Ժ����������½�ĵڶ����˻���սЭ�鲻��֡��ȸ�һ����ǩ����Э������磬���й���ԺҪ��ȸ�ų���������й�������Ҳ������
�����ȸ��AlphaGo�������ˣ��ų������Բ��±��ҵ�bug����������Ӧ��������������Ȼ�ķ�չ��ʱ��Ҳ�Ե��ϡ�һ����Ȥ��ϸ���ǣ�������Ե������У���̩��ֻ��ù�һ�����ڹھ���������ھ���ˮƽ����һ�㣬������ȴ�л�����Master���������塣�Ҳ²�������Ϊ��Master��AlphaGo�ġ������е�ۡ������߶��ǹȸ����ĵ�����֮һAja Huang����������WeiqiTV����̩��Ľ�Ŀ�������ķ�˿����˶����������Master�Ծ֡�
����Ҳ��˵Master�����Ǻ����з���AI����������Լ��͡�Χ��AI���з����й켣�ģ�����Ѷ�������չȸ����Ŀ��ٴﵽ�ܸ�ˮƽ�ǿ�������ģ�����Ҳ��Ҫ���������ҵ������ֻ�ͷ��취����̫������ͷ�з�һ�����������С����ȸ辭������汾��������ȷʵ�����ʵ����2016���У�Deepmind��ѧ�������Ͼ����ƺ����汾����V18�ĸ����ˣ���ȡ���˾������
����Master���50��ʤ��δ��ֹ���壬1��4�������ּ�����ս���������ʤ��������Masterֻѡ��30��Ŀ��壬�����������˵˼��ʱ�䲻�����Է������ˮƽ����Master�̶���ÿ8����һ�Σ�ʱ�����û���꣬���ǻ�����Ȼ�����ơ�������ֶ�սʱ����ѡ��20��Ķ��룬30����������ʱ�䳤���ˣ�����������ϰ�����ڶ�Master����ս�Ѿ������˱�׳ɫ�ʣ�����ʽ�������ջ�Ҫ���ң�Ұ��Χ��Ĵ�ʼ�˹����Ŷ����Ƶ�һ��սʤMaster���˽���10��Ԫ��
��������Master���������ߣ��ֲ�����������ϰ�ߵ���·���ܶ���涼��Ҫǿ�ȼ����˼����30���������ʵ���Dz������������©������ˣ��������30�����֣�Master��ʤ����һֱ������ȥ����Щ���빦��ǿ�����ֺųƿ�����ˮƽ��࣬��������������һЩ������·�ж�ս�����Ҷ��빦��ǿ��˵�����������������ǰ��������������ͣ����ǵ�ͣ����˼����10�����Ӷ���̵ģ���Сʱ��1Сʱ���ϵij���Ҳ������
������ͼ��1��3�տ½���Masterһ��ս����һ���䡣�½�������ζ��루һ��������30�룩�������Ͻǵ�ս���ж�ס�ˡ��ڳԵ�������Ŀ����С����Ҳû�а�����Ӧ�������Dz������MasterҲѡ���˼��ҵ��·����½�ֻʣ��һ��30�룬Ӧ�Բ�������ˡ������͵�ս���У��������ֻ����ᱻMaster��塣
������ˣ�Master���������ˮƽ����ȡ��50��ʤ�����ʵ�����˹��ڿ��š�Χ��AI���㷨�����ǣ������ռ���ָ�������ģ���ʮ��ʱ��ֻ�Ǵ�������������Ӽ��㣬�������뼸ʮ���ӵ����������������ޱ�������������ʱ��������������MCTS�����ģ���վ�������ģ������������һЩ���ﵽ����ʱ����֤�㹻�����������ģ��ľ�������֮��������ʱ�����岢��̫��
����AlphaGo�ڷֲ�ʽ�汾��1202��CPU��176��GPU���ȡ������桱��48��CPU��8��GPU���༸ʮ�������ǶԵ������ʤ��70%��û�б�������������ʵս֤����Master������˼���������ʮ������л�����ˮƽ�ˡ�����ܹ�սʤ�����¡���AI�汾��սʤ˼��ʱ������İ汾û�б��ʵ����ѡ�
�������������Ⱥ�������Master����ʽ�ĵ���������ȫ�ܣ����ֳ���һЩ��ȥ���ܲ�̫���ӵ����㣬ֵ�úú��ܽ���������Ĵ�Χ�������롰�����ϡ��ĽǶȽ��м��������ǰ��������ʽ�Ľ��ܣ��Ķ���������ݾ���Ҫ��Χ�弼���������㷨��һ�����˽⡣
����AIɱ��ﵣ���ֵ����Ͳ�������
�������������Χ��Ĺ��̺ͻ���������ֶ��ǿ��Բ��յġ����ڵ�ǰ���棬������ֱ������һЩ��ѡ�㣬���Ӧ�������и�ˮƽΧ��AI�����õ����ѧϰ�����ġ��������硱������ѧϰ���ɲ�������ʱ���ο��ľ���������ֵ���֣�Ҳ��˵����AlphaGo���㿪ʼ���ο�������֣�ȫ������ǿ��ѧϰ���ɲ�������ġ����Master�����������������������ĺ�ѡ�㷶Χ�ڵģ�������Ϊ���ֺ�Master��ʤ�������ں�ѡ���������
����������ֻ���������˼��ʱ��Բ���һЩѡ����м������ݣ�������ߵ�ֱ�������࣬��ʱ���Ƶ���ʮ���Ժ�Ȼ������ǻ�����жϣ���������桰�������������Լ����ƿ��Խ��ܣ�����ô���ˣ��ٺ�Щ�ܸ����ָ��ݴ����Ҳ��ȥ���ˡ������жϾ��桰���ӡ������壬������dz����صؾ����������־��棬Ѱ����Ȼ����С�����Լ��ܿ��ƵĴ����취��Ҳ��һЩ���ֻ���������ֵ��븴�Ӿ��棬�����Լ���ս�ij�����
�����������о�����жϵ���Ҫ�ֶ��ǡ���Ŀ������ȷ���ĵ�������������Ĺ����ǽ���Ŀ�жϾ�ϸ���ij̶��Ƶ��˼��£���Ȼ���ڵĸ����ⷽ���ˮƽҲ�����ˡ�����Ŀ�Ժ�������Ŀ��˫������Ŀ����࣬������չٽβ���Դ�����Ŀ���ϣ�����һ���ȷ���ˣ�ʤ���Ѷ���ʰ���顣�ڲ����Լ����̣���Ҫ�ú��ơ����帺��֮������ص���һ�£��ִֵĸ������ۡ�
�������ֽ��������ܲ���ȷ����ͬ�������жϿ��ܲ�ͬ���е�ϲ��ʵ�أ�����ǡ�����ʵ�ء�������ϲ�����ƣ�����ǡ���ʵ����������������ʱû���ж��˻����뽲�����������ϲ�����ձ����߷����ġ��ָ�����ӹ����н��۵ľ���Ϊ�������ı����ִ����ƣ��е���ѧ����ϵͳ����˼����֮���ھ��滹�кܶ�δȷ�����ص�ʱ����������жϵ��ֶξ�����Щ������̫�ࡣ
������������£�������������۾����жϵ�ʱ����ʱ�Եúܸ�Ц�ġ����һ�����棬��A����B�����ȷ���ġ���A�����B��1Ŀ���������и��ֶ�����ΪA�Ǵ��в���������ʱ������Ϊ����һĿ���������ܡ��Ŀ�����и��ӵĴ�ת�������߷�һ����ʽ��
����������ֶ�����ȷ�����۵Ķ����Ƿdz�����ġ���Ҳ�Ƕ���ҵ�����ֺ����Ϳ�ĵط�����B������A����Ҳ��ƾ�о����ɣ����¾Ϳ����ܶ�Ŀ�����������ʱ������һ��ѡ��C��û�а취���AB����ȷ�����ۣ��Ǹ����Ǿͻ����������֡�����˫�����¡�������ʧ������������C���ÿ��ƻ�����B��������C�չ˴�֡�֮���ģ�����ۡ�����ʵ���Ͽ�����C����BҪ�õö࣬���ѡ��B���ľͲ���1Ŀ�ˣ������Ǻü�Ŀ��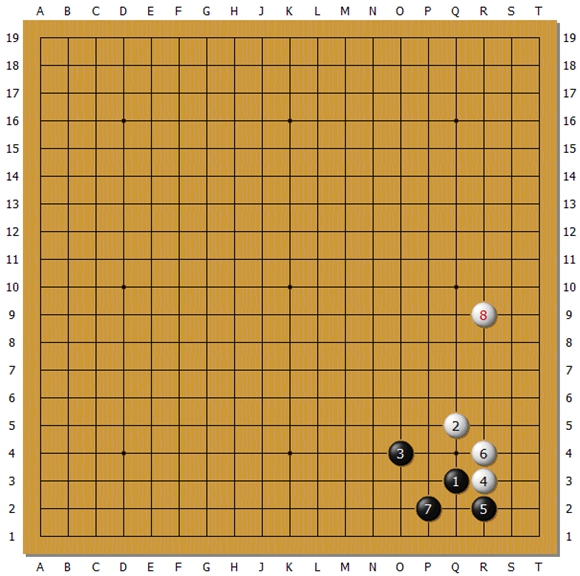
������ͼ����ǰ��һ������СĿ��ʽ���������¹������̡����Ǻ���û�������ˣ���Ϊʵ�������ͼ��������ˡ�˫������һ�����ڻ���ռ�ǵģ���������λ��ƫ�ͣ��غ��ƶ������������ƣ�û�����֡��������ơ�����������ô���ͣ�����֮ǰΪʲôһֱ�£���Ϊ����Ҳ��������ô���ԡ���̩��˵���Ǹ����Ǿ������ʵս������ִ��һ��ʤ������ƫ�ͣ���ͷ�����⣬��ŷ����������ʽ��
�������֡�����ʵս���жϣ�������Χ��ʱ�������ǿ��������°취��˵���壬��Ҿ�ʵս�����ԣ���˵���֣���˵���ţ�ˮƽ�൱��˫��ʵս100�������ʤ��70������ռ�ţ���һ��ǻ�ͬ�⡰���š��Ľ��ۡ���ǰû�����磬ְҵ����һ����¼�ʮ���壬���ཻ��Ҳ�٣����ַ����Ͳ������ˣ������Ǹ������ʽ��ϸ�����������ӡ���������ʱ�����ڷܵ�ְҵ����һ������ǧ�����嶼�п��ܣ����ַ����������ܣ�������������Ȥ���ݱ䡣
����������Ϊ��ά��״̬���ͻ���������վ����20��30��Ŀ��塣�����Ľ���ǣ������ǿ����ݱ����һЩ���͡���·����������Ϊ�������ƫ����·��һ���Կ�����ͨ���������ֱ�ӽ����ж�֤�������Ǵ�Ҷ�����·����������̶ȡ�
����ż�����и��ֳ������֡�ȡ��Ч�������������������о������Ժ�����Ӧ��Ӧ�ԣ���������֣��ḻ����·���ں�������ͬ��������ֳ������γ��µ���·����ͷ���ϵ���·���������ط�����·������ȷʵ���ˣ�Ҳ�����������յĽ��������������Լ���ʽ�Ծ֣��ͳ����˴�����·̫�࣬������־��ʳ̶ȵ����⣬��ʱ���������̡�������ʮ�ֲű��У�Χ���С����廯�������ơ�
������Ȼ��Щ��·�����ں��ġ�һ����Ϊ�ձ�����ˮƽ����к��½�������Ϊ�ձ�����ս�������У����ֿ��Ż��У����̾ͱ�ɱ�ò����ˡ���̩��ս��������·���������ֱ���Բ���Dz��ַ���ȴ�������ģ�����սʤ��·�õĶ��֣����й��ȼ�������20��λ������Ϊ�ձ�����ǡǡ�Dz���ˮƽ�����⣬�Ծ������������ˡ���Ϊ�к����ֻ����������϶�ս�������ڹ��Ҷ��サ�����¡���·���ں��ɹ���������ʵ�����˺ܶ��Ƚ�֪ʶ��
�����ձ����ֻ�������·��Ҳ��ע����Щ���³ɹ������ǰ��ϵ������߳��˿�Ҳ��֪�����������ǡ�������������Ҫ�����³����ֵ�������ս�����ֲ��У���ø��졣
�����к������Ǽ���ʵս��֤��·�İ취����ʵ������AlphaGoǿ��ѧϰ���ɼ�ֵ����ķ�����AlphaGo����м�ǧ��εĸ����������ҶԾ֡����ȸ����ǵĶԾּ���������öࡣ��������Ƿ���ʵս���жϼ�ʮ�����涼�����ף�AlphaGo��ѵ����ˮ��ȴ�����ɼ�ǧ������棬���ڼ�ֵ�����ѵ����
������ֵ�����Ǹ��Ͳ�������ṹ���ƵĶ�������磬���������ϵ����һ�������ܶ�һ����̬���治����ֱ�Ӹ���ʤ�ʣ��ж�˭ռ�š����˲����������ֵ���磬AlphaGo����Ҫ�����������µúܺ��ˣ���ÿһ�в��������ṩ��ѡ�㣬��ֵ�������ʤ���жϣ�ѡ����õ�һ��ѡ���¾Ϳ����ˡ�2016����Deepmind˵AlphaGo����ȡ��ͻ�ƣ����ر�˵�˼�ֵ����ȡ���˾�Ľ�����
������ֵ����������˼����û�еģ��ڹȸ�����֮ǰ����û����������ѧ���Ƕ���˵��������ǹȸ��������Ĺ��ף����ѧϰ���ɲ������Բ���Deepmind��������ġ���Ȼ��������˵�е㲻��Ȼ������ֵ���������������ѧϰ�ĵط���ְҵ������Ҳ���ܴ����������ȡ��������ͻ�ƣ�����Ҫ��ѧ�ķ�����
����������ͨ�����ʵս�����ף��������γ�ֱ������һ�۾�����ܸ������β���һЩ���ĺ�ѡ�㡣������ֱ������֮�����ڣ���ѡ���С��ֲ��ԡ�����ֻҪ���ֲ������С��ؼ������ֱ������ʱһЩ�չ�ȫ�ֵ����лᱻ���ŵس�Ϊ���������֡���������Ȼ������Ǿֲ��۲죬�۾�������ʱ��Ȼ��۽���һС��ط�������˼άҲ����ˡ�����Ҫ�������ֱ���۲�ȫ�֣�����һЩ��ѡ�㡣���������й��Ŵ�ˮƽ��ߵ�����֮һ���������������������������գ�����������ֻһ�棬���������棬�����������������ܵ���Ҳ��������˵������ȫ�ֹ����ر�ǿ��
����������ȫ�ֹ���Ͼ��������������˸�����ֻ�������Դ��ġ���ֹۡ�������Ծֲ��ľ�ȷ����ȴ����ȡ�ý�չ���ֲ���ʽ��չ����ǧ������������С���ʽ��ȫ���������顣�ֲ���Ŀ���ֶ��뼼��Ҳ���Ϸ�չ��Ŀ����ֵ��ȷ������֮һ����ֹ۷���ȴһֱû��̫��Ľ�չ������һЩ90�����������Ϊ�����ֲ�Ҫ̫���أ���ʱ����Ҳ�벻��ʲô�������������·������һЩ����ȥ������Ӧ���£�����ʱ��Ҫ�����к��̾�ս��
������ʵս��˵����Ҳȷʵ��ʤ�ʽϸߵ�ѡ����������·δ��ռ�ţ����㻨����ʱ����ĥ����ѡ�����������Ŀ������ʱ�䲻������ʱ���̣���Ϊ�˼Һ���϶���������������̩����Ҫ�Ļ�ʤ��ʽ����������һЩ�������ֺ��Ӳ�������ص㣬�������о����֣�����ھ����ж���ȡ�����ƣ�����ƴ������������������������������������dz��ʵ��̫��������������ס��̩��Ҳ��ȡ��ս����ͻ�ƣ�ֻ��ά��סһ�����ֵĵ�λ��
����ְҵ����������ѵ�������뷽���ĸ���
����ְҵ������ˮƽȡ��ͻ�ƣ�Ҳ��һЩΧ��������ϸ���»�ѵ���ֶηֲ��������С�������������������⣬������д����ĶԾ֣��Ͻ������̬���������С��������硱������������������������ǧ�����ʷ���ۣ������ʵս�ṩ�˴����زģ����в��ٸ���ϲ�����������⡣�ձ��ġ������ۡ��������й��Ŵ������в����زģ�����������ͼ����ʵս���ۡ��������زIJ�ȱ���е����������磬��ˮƽʵս�����Ļ��ȱ����·��ص���Ϣ����Ҳ�죬ְҵ����Ⱥ��ˮƽѸ�ٽ�����
�������ǣ���������û�ж��١������жϡ�����Ŀ���ۣ�����һ���dz����صļ�����ȱʧ���������Ⱥ������ʶ�����ⷽ��Ŭ�������а취����ġ����Լ�������һЩ���棬ȡ��һ�£��ó�����Ϊϰ����ߡ�ѵ����������Ҳ��������������֯ʵս��������һЩ����ͳ��ʤ�ʣ���ñ�������ݣ����һ�¡����Ի��۴�����վ��ʵս��ˮƽ���ף���һЩͬ��ֽ��д����ݷ����������ķ��������Ѿ����ˣ�����Ҫ����ʽ�������ײ����࣬����ܺͶ�����վ���֣����Ӻ������ף�����ͳ�Ʒ�����Ϊ��ȷ��
�����������˸�ˮƽΧ��AI����Ϊ�����ˡ���ˮƽΧ��AI���Ժ�һ�����ռ�������ſ�AI���ݺ��ţ����ܿ�������ľ���ʤ�ʣ�������ֵ����Ծ���Ĺ�ֵ������Ҳ����ѵ���õļ�ֵ���絥�����������С�������������������Ӧ�ÿ�����������һ�����۳������ľ����ж��زġ�����ǰ��һ�����ǣ���Щ�����ж����вο��𰸣����ΪȨ���Ĵ𰸣�����������˼���⡣
����ְҵ�����ǿ���ȥ������Щ�����ж��⣬����ȫ��˼����Ϊʲô��Щ�����Ǻ��Ų��ǰ��ţ�Ϊʲô���Լ��ĸо��෴��ΪʲôAI����ͳ�ƽ������ԣ��Լ�ȴû�ио���������ϸ��ĥ��һ�������һЩ��������ĥ���ˣ����������жϵ��ٶȶ���ӿ졣AI�IJ�������ͼ�ֵ����������������Ƶģ������Ȼ�ܹ��С��������硱��ֱ��ϵͳ��ͬ����������ѵ��������ֵ���硱Ӧ���ǿ��еġ�
����������ȼ�����ߵĿ½�����������������ܾ����������ص㡣�½����·����������ģ���ĿҲ������ǿ��Ҳ��������һ�ѣ���Ȼ��Щ���������½��Գ���ǿ�����жϣ���ʱֱ���жϲ�����Ŀ��֪���ǿ��˻����ˣ���ͨ��4000��������ɳ������ġ��ܿ��ܿ½�����ǧ�̶�ս�в��Ծ���ע���˶����С���ֵ���硱��ѵ�����γ����Լ�����������ֵľ����ж���������Щ������������Ϊ���½����µ�����AI�����֡�
����ְҵ����Ⱥ�����������̹��̻��������ռ�����������ķ�ֱ�����棬�����������������ƻ���ѧϰ�ġ�����ѧϰ��ѵ�����γ�ֱ��һ���ľ����ж��������ڸ�ˮƽAI�İ����£��������Ӧ�ÿ���Ѹ�����̣����÷dz�����ػ����زġ��Ը�����������ѵˮƽ���ԣ������ж��ز��Լ�ʹ��AI����ѵ�������������Ϊ��Ҫ���ء���������AI�������������������ѵ���ˡ�
�������־����жϣ���������ȫ�ֵġ��⽫ʹ������ֵ�Χ��˼ά����֮ǰ�ľֲ���ʽ���ֲ���Ŀ���ֲ�ս������Ծ������ȫ���жϡ�ȫ��ս�����⽫������Դ��ʦ�����֮��˼�������Ƶġ�21����Χ�塱��������Χ�塱ʱ��������Դ2014��ȥ���ˣ�û�п���Χ��AI�ĸ����Խ�չ��������Χ��AI�İ����£����ʱ�������ɱ���ĵ������������Χ��ˮƽ���ٴ�ȡ��ͻ���Խ�չ��
����������Master������Χ��AI��Ҳ��Ҫ���ڿ־塣�����������������Լ�ֵ����Ϊ������ȫ��˼ά�����ֲ��ϣ�����ȡ�ᡣAI�ļ�ֵ�����ǻ���ȫ�ֵģ�����ȫ���������в�ͬ���������־ͻᷢ���仯��ԶԶ�ļ���ɢ���������ʲô��AIȴ�ܿ��ǵ��³����֡�
�����������30�����ʱ����̣�������������ȫ��ͬ����·��Ҫ���㣬��Ȼ���׳������ݺݴ����������Щ���֣���������ǡ���֪��AI��ʲô��˼��������һЩ�����ŷ��ֳԴ���ˡ���Щ����ĸ����������ڿ־壬���Լ�ʧȥ���ģ����Լ������Σ�����ʹ���ˡ�
�������������������������ƣ���Ҫ�����˼��ʱ�䡣��̽��Χ�弼�յĽǶȣ�Ҫ�����˼��ʱ���Ǻ����ġ�����ڲ���������ս�������Ȼ��߶�ס�ˣ��չ�ʱ��ʱ����ų�С���ܱ����Ⲣ�����¡�������������ڲ��ַ���ѡ�Ӵ�ս�ľ����ж��и��������ȫ��˼ά���ӽ�AI��ˮƽ�����л��ᶥס��
����AI����MCTS�㷨���������㣬�ܴ������Ȼ����ȱ�ݵģ�̫���ӵľ���������·���⣬���߾ֲ��������©�㣬��������������ơ�
��������������������������ֲ�������·�������Ƶģ����ڸ��Ӿ��棬��������ܽ������Ҫì�ܣ���Ƴ�����ֶΣ����������д���AI����MCTS�Ŀ�����ԣ�ʲô��Ҫ�㵽�վ֣�������ʲô��ģ������������˷��ڷǹؼ����������©���ǿ��ܵġ���Ȼǰ�������������Ҫ��ס��������AI��������10��20Ŀ����AI���Լ����ؿ��ƾ��棬���ֺ����ᡣ
���������������ܹ�ѧϰ��ֵ�����ȫ��˼ά����ѵ����ȡ�����յķ�Ծ�������ٸ����㹻��˼��ʱ�䣬��AlphaGo�Լ�����ˮƽ���Ͻ����ĸ�ˮƽAI��ս������ʤ���ģ������Χ�巢չ�����弫Ϊ�ش�Deepmind������AlphaGo�����ĸ�����Χ�����ȷ�����ɵ�����Χ��������һ�εķ�Ծ��������������Ҳ������dz��
���¾�����Χ��AI��ɨ�� ְҵ���ָ�������ˮƽ��������������-ԥ�����ṩ��ת����ע��������http://news.yuduxx.com/shwx/746559.html��лл������
ԥ������Ȩ����������
1��δ��ԥ���������¼�Ʊ��������ɣ��κ��˲��÷Ƿ�ʹ�ñ������а�Ȩ��Ʒ��
2������ת������ý��֮������Լ����û������ϴ�����Ʒ��������������ͬ��۵�Ͷ�����ʵ�Ը���
3��������Ʒ��Ȩ�������������ϵ����������ȷ�Ϻ���24Сʱ���Ƴ�����������ݡ�